声音如何变成了数字
大吼一声,发生了什么?
听过三国评书的朋友,都知道“张飞喝断当阳桥”的故事,可见声音大到一定程度还是很吓人的。那么声音是怎么产生,又怎么传递和接收的,考虑到系列文章面对的中老年人不一定系统的学过,这里还是要多讲讲。
首先说声音的产生,以张飞大喝一声为例子,人的声音产生,是由喉咙里的声带导致的。声带么……可以简单想象成一片肌肉薄膜,它位于人的喉头部位。人在发声的时候,会运用气流冲击声带形成振动,同时大脑控制肌肉会进行变形,引发振动方式不断改变,声带振动又引起口腔空气振动,再经过舌头、嘴唇的共同作用,从嘴里跑出来,形成不同于原来形式的振动,就是一系列音节“啊,喔,鹅,衣,呜,鱼……”。
弹过琴的朋友更有经验,琴弦在拨动之后会发出声音,此时用手制止了琴弦的振动,声音马上戛(jia)然而止。所有的经验表明:声音是振动产生,这种振动也需要借助什么东西进行传递,传递声音的东西称为介质(媒介物质?)。空气是介质,桌子也是,墙壁也是(半夜楼上有人走来走去是不是很烦),水也是但不很有效。好不容易从喉咙里发出振动,在空气里传播受到阻力,最后离你10米就没人能听到,是不是很气馁(振不动了),比起张飞还是差远了。
那么我们的听觉就是个反过来的过程,耳鼓膜接收到振动,再转化成神经元电信号传递到大脑(实际比这个复杂一些),大脑把信号翻译成能理解的语言,然后再指挥嘴巴出言反驳:“你才有毛病呢”。我们就完成了一次完美的沟通。
小学自然课可能只会讲到这里,我们再深入一点,那么声音的大小和不同的音调才是关键,要不然每个人能发出的都是“啊~~~~~~”这样毫无意义的音节。“她的歌声像百灵鸟一样好听”、“这个人五音不全我们还是假装不认识他吧”。
声音的大小(专业叫法:响度),其实取决于振动源头振动范围的大小,也就是声音里能量的大小。就好比唱歌时候,轻轻唱“~哆~来~咪~”,大声唱“~哆~来~咪~”,那么引起的振动大小就不一样。你和张飞其实差的就是这个,他的振动像一块巨石一样砸到小桥了。响度越高,传的越远。
另一个概念是音高。音高对应到振动上,就是指振动物体振动的快慢,衡量这个快慢的单位叫做“赫兹(Hz)”——19赫兹表示1秒振动19次。C调的“哆”定义为“440赫兹”,而我们人耳朵能听到的振动范围是20赫兹-20000赫兹(不同的人不一样,当然能否听到还取决于“响度”)。低于20赫兹叫做“次声波”,高于20000赫兹叫做“超声波”。一个人唱歌的时候,能完美控制住哪些“赫兹”,就决定了这个人的“音域”宽广不宽广,唱的“在不在调上”。特定的频率对神经有特定激发作用,比如婴儿哭声即使很小母亲都能听到……
第三个问题是音色。为什么韩红和李娜唱的《青藏高原》,一样的音高(都在调上),差不多的响度(都很嘹亮),我们一下就能分辨出来是谁唱的?这就是音色在作用。上面的“响度”和“音高”,都是描述单音的本质。每种我们听到的声音,都不是简单的单音,而是多种声音的复合音。里边包含主要振动和次要振动,无论是主要振动还是次要振动,都可能会有好多种。这些振动的方式,和振动物本身、引起振动的方式等都有关系,主要振动响度比较高,次要振动响度比较弱,这些声音复合起来,传到我们耳朵里,就构成了一种独特的声音,才能分辨出钢琴和唢呐,到底是妈妈还是爸爸。小知识:声乐专业也是根据音色来区分高中低音歌手的,并不是说男低音就唱不上去高调。耳朵能分辨40万种声音,相当厉害了。
好了,现在我们理解声音的本质其实是振动,你站在地上骂老天爷,TA是听不到的,因为我们和天宫中间隔着茫茫宇宙,真空没有物质,也无法传递振动。相反你要是骂阎王,很可能就被听到了……
我们把声音的原理:振动,绘制成图,用曲线图来表示:(专业名字:波形图)
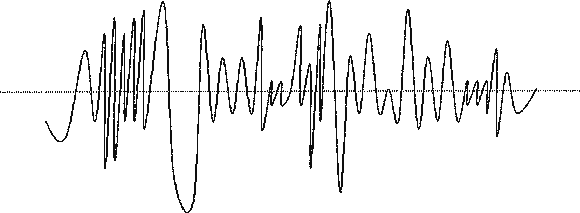
这个图里边,纵坐标(波形高低)来表示响度(幅度变化越大声音就越大),横坐标表示时间,音高比较高的地方,在横坐标上就越密集。而音色,就是多种这样的曲线叠加到一起形成的。为了简单一些,我们下文不讨论音色,只针对单音进行讨论。
下面是难以理解的概念
好,经过第一阶段的抽象,强行认为你们理解了声音,也强行认为你们能够把波形图看成了声音。那么这里要说个比较难理解的概念:连续和离散。
看上去好像数学概念,其实也比较好理解。连续就是指一根线条,离散就是一个个的点。聪明的你一定会说:线条不就是一个个的点组成的么?Good,你已经入门了。实际上还是有区别的,那就是:一根__连续__的线条可以分成__无数__个点;而__离散__的点即使再多也是__有穷尽__的。可以用很多的点去模拟一个线条,但无法等于这个线条。结论是:自然是连续的,数字是离散的。数字只能尽力去模拟自然,然而终究无法等同。那么声音和数字声音也是这种关系。
对应到上面那个波形曲线图,声音实际上是连续的。人们发现了声音振动的秘密之后,就通过各种方法来延长这种振动。后来有了电,贝尔把声音振动转化成不断变化的电流,通过导线传递到另一端,另一端再把变化的电流变成变化的振动传出去,这个技术逐步改进,就成了最早的电话;爱迪生发明留声机的原理也是如此,把声音转化成一种振动,用短针把振动刻到某种材质上形成深浅不一的槽,播放的时候反过来,短针把槽里的振动传递出来变成声音(注意,最早的留声机是纯机械结构,持续改进以后才有了电留声机)。从这个历史看出,声音无论是转化成大小不同的电流,还是深浅不一的槽,本质上都是一种连续的记录。那么连续的东西怎么变成离散的数字呢?这就涉及到连续和离散的转换。(并不是涉及到电,就是数字概念,数字本身是离散的,而变化大多是连续的)
幻化成波形曲线的声音__毫无规律__,非常遗憾,数字机器无法记录__没有规律__的连续数据(因为是无穷数,但是有规律的连续数据可以通过数学公式来记录)。所以数字机器记录声音的时候,只能用从这条波形曲线上取很多很多的点。当这些点“密集”到一定程度,也就和真实的声波振动曲线差不多了,然后这些“离散”点转换成数字坐标,就可以用数字机器来存储、处理和传递了。
再看上面的波形曲线图。假设这是一首3分钟的歌曲,那么我们在这条曲线上密密麻麻取1亿亿个点(实际上用不了那么多,这个过程叫做“采样”,就是采集足够多的样本),然后用数字记录下每个点的坐标位置……完成了声音到数字转换。
有时候我们用微信给别人发语音,别人听到后会问:这tm是你的声音吗?原因是:采样越密集,所需要的点越多,占的地方就越多;微信为了节省手机流量,选的点比较少,采样不那么密集,形成的声波曲线不那么圆润,响度(波形高低)和音高(波形频率)还能基本保持原样,但是音色就会损失不少。。。所以你的声音失真了。
好,回忆一下本节内容,
-
录音过程:振动传到了话筒,话筒把振动变成了电信号变化曲线(有些话筒可以直接转化成数字信号),然后由数字机器在曲线上进行足够密集的取点(采样),记录每个点的数字坐标,这些坐标数字集合起来就形成了声音片段;
-
播放过程:录音过程反过来,数字机器先拿到数字声音片段,里边有个坐标集合,然后按顺序把坐标组合起来,形成近似原来曲线的一个波形,再把波形转成电信号,驱动发声设备进行振动。
原理到此结束,感谢你看完。
进阶
数字声音都是对真实声音的波形曲线“采样”来的,有两个标准来评判采样,一个叫做比特率(主要决定纵坐标的细分程度),一个叫做采样频率(主要决定横坐标能细分到什么程度)。这两个数字越高,采样点能模拟的曲线就越接近原曲线。音乐CD的比特率(16比特)和采样频率(44100赫兹)可以看作一个分界线,比特率和采样频率超过CD的,可以看作无损音乐,低于CD的,可以看作有损音乐。至于mp3,甚至会删除掉人耳朵不敏感的声音频率以减小体积。如果遇到一个非要在概念上较真的人,想听“真正”的无损音乐,只能请TA去音乐会现场了……因为目前所有的数字音乐,都无法做到一丝不差的还原。其实就算我们直接听音乐会,空气中也会损失一些振动特性吧……
小知识
上面讲到,真空没有介质,声音就无法传递,那么太阳光是怎么越过宇宙真空来到地球呢?原因是:光既是物质(光子),又是振动(光波),光一边前进,一边振动,因为有物质特性,真空没有介质也能传递……现代物理只能解释到这里啦。